A ideia deste post é demonstrar como fazer uma carga de tabela fato onde seja necessário inserir, atualizar e deletar linhas. Ao invés de realizar os comandos INSERT, UPDATE e DELETE separados podemos através do comando MERGE realizar as 3 operações na mesma query!
No nosso exemplo temos um data warehouse com as seguintes características:
- Recebemos uma vez por mês do sistema de origem os dados consolidados dos últimos 3 meses;
- As novas linhas na origem precisam ser incluídas na nossa base;
- As linhas que tiveram valores modificados precisam ser atualizadas;
- As linhas que forem excluídas da origem também precisam ser removidas da nossa base, porém somente dentro do período que foi enviado.
Abaixo temos a imagem dos dados atuais nossa tabela FATO_VENDAS:
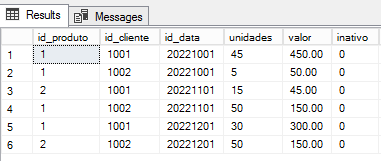
E a seguir os novos dados que recebemos do sistema de origem:

Analisando as diferenças entre as tabelas podemos perceber que tivemos 2 linhas novas, 1 linha atualizada e 2 linhas excluídas, conforme o desenho abaixo:

Para solucionar esta carga de acordo com os requisitos iremos utilizar o comando MERGE da seguinte forma:
/*Criando parâmetros para somente atualizar
linhas dentro do intervalo que veio da origem
(manter histórico que não sofre alterações fixo)
*/
DECLARE @dt_inicio INT =
(SELECT MIN(id_data) FROM #tmp_fato_vendas)
DECLARE @dt_termino INT =
(SELECT MAX(id_data) FROM #tmp_fato_vendas)
--Comando MERGE para carga da tabela FATO
MERGE INTO #fato_vendas AS f_TARGET
USING #tmp_fato_vendas AS f_SOURCE
ON f_TARGET.id_produto = f_SOURCE.id_produto
AND f_TARGET.id_cliente = f_SOURCE.id_cliente
AND f_TARGET.id_data = f_SOURCE.id_data
WHEN MATCHED
AND f_TARGET.unidades <> f_SOURCE.unidades
OR f_TARGET.valor <> f_SOURCE.valor THEN
--linhas existentes que tiveram modificação
UPDATE
SET f_TARGET.unidades = f_SOURCE.unidades,
f_TARGET.valor = f_SOURCE.valor,
f_TARGET.inativo = 0,
f_TARGET.dt_modificacao = GETDATE()
WHEN NOT MATCHED BY TARGET THEN
-- linhas novas
INSERT (id_produto,
id_cliente,
id_data,
unidades,
valor,
inativo,
dt_modificacao)
VALUES
(f_SOURCE.id_produto,
f_SOURCE.id_cliente,
f_SOURCE.id_data,
f_SOURCE.unidades,
f_SOURCE.valor,
0,
GETDATE())
WHEN NOT MATCHED BY SOURCE
AND f_TARGET.id_data BETWEEN @dt_inicio AND @dt_termino THEN
--linhas existentes que foram apagadas da origem
UPDATE
SET f_TARGET.inativo = 1,
f_TARGET.dt_modificacao = GETDATE();
Feito o comando MERGE, o resultado final da tabela FATO_VENDAS deverá ficar conforme abaixo:

Observe as duas linhas excluídas ficaram com a coluna [inativo] = 1 (deleção lógica) e que as linhas inseridas/atualizadas tiveram um novo valor para a coluna [dt_modificacao].
O script completo para reproduzir com os mesmos dados do exemplo está disponível no Github.
Referências:
MSSQL Tips – Using MERGE in SQL Server to insert, update and delete at the same time
SQL Server Tutorial .NET – SQL Server MERGE
Microsoft Learn Questions – Merge WHEN NOT MATCHED BY SOURCE