Atualmente as áreas de análise e visualização de dados geográficos vêm sendo bastante exploradas por analistas, estatísticos e cientistas de dados devido à quantidade de recursos disponíveis e pela facilidade no entendimento que é proporcionada ao visualizar dados sobre mapas.
Neste post vamos demonstrar em 7 passos como gerar um mapa do Brasil interativo, usando a ferramenta R, para apresentar a distribuição dos pontos ganhos pelos clubes no Campeonato Brasileiro de futebol desde 2003, na visão por estado.
1) Fazer download do shapefile do Brasil no site do IBGE
Inicialmente precisamos importar para o R o shapefile do mapa do Brasil, que está disponível no site do IBGE. No exemplo vamos utilizar o mapa com a distribuição por estado, porém no site há diversos outros tipos de mapa, como mapas de cada estado com divisão por município, entre outros.
Para encontrar o mapa do Brasil por estado, vamos utilizar a URL abaixo e navegar pelo diretório de pastas do site até encontrar o arquivo br_unidades_da_federacao.zip (imagem a seguir):
http://downloads.ibge.gov.br/downloads_geociencias.htm
Vamos navegar pelo seguinte diretório:
organizacao_do_territorio >>> malhas_territoriais >>> malhas_municipais >>> municipio_2015 >>> Brasil >>> BR >>> br_unidades_da_federacao.zip

Diretório de pastas no site do IBGE
Após fazer o download, iremos extrair os cinco arquivos e copiá-los para o diretório de trabalho do R (no nosso exemplo, será criada uma pasta chamada “Mapa”), para que assim eles possam ser importados.
2) Importar o shapefile para o R
Agora temos que importar o nosso shapefile para o R, atribuindo a uma variável chamada “shp”. Utilizaremos a função readOGR para esta tarefa:
shp <- readOGR("Mapa\\.", "BRUFE250GC_SIR", stringsAsFactors=FALSE, encoding="UTF-8")
Podemos verificar executando o comando class(shp) que o objeto “shp” é do tipo “SpatialPolygonsDataFrame”. Este é o tipo de objeto que precisamos criar para gerar mapas no R.
3) Importar o dataset que possui os dados que serão plotados no mapa
Outra etapa necessária é importar o arquivo que possui os dados que queremos exibir no mapa. No caso deste exemplo, temos um arquivo chamado “ClassificacaoPontosCorridos.csv” que tem dados dos pontos ganhos por cada clube no Campeonato Brasileiro desde 2003.
O script abaixo realiza a importação do arquivo e realiza a sumarização dos pontos ganhos por estado, utilizando as funções do o pacote dplyr:
pg <- read.csv("Dados\\ClassificacaoPontosCorridos.csv", header=T,sep=";")
pg <- pg %>% group_by(Estado) %>% mutate(cumsum = cumsum(PG))
pg <- pg %>%
group_by(Estado) %>%
summarise(Score= max(Score))
pg <- as.data.frame(pg)
Podemos verificar executando o comando class(pg) que a variável “pg” é do tipo de dados “data.frame”. Este é um dos tipos de dados mais comuns no R para armazenar tabelas, porém para trabalhar com mapas precisaremos unir esta variável ao objeto de tipo espacial criado no passo 2.
4) Importar os códigos do IBGE e adicionar ao dataset
O shapefile do IBGE que importamos no passo 2 não possui o campo “UF”, que é o campo utilizado para identificar o estado no nosso dataset. Teremos então que utilizar um campo chamado “CD_GEOCUF”, que é um código numérico do IBGE para identificar o estado. Para conseguirmos relacionar nosso dataset com o shapefile, iremos realizar a importação de um arquivo CSV que tenha estes códigos numéricos e realizar um “merge” entre este arquivo CSV (variável “ibge”) e o nosso dataset (variável “pg”), para associar os dados pelo campo UF:
ibge <- read.csv("Dados\\estadosibge.csv", header=T,sep=",")
pg <- merge(pg,ibge, by.x = "Estado", by.y = "UF")
Após esta operação, o data frame ficou conforme a imagem abaixo:
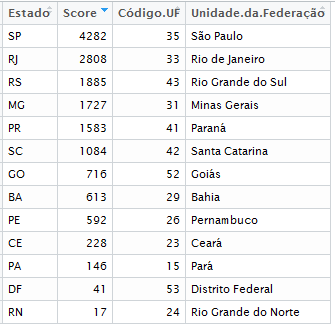
Data frame com o campo “Código.UF”
5) Fazer a junção entre o dataset e o shapefile utilizando o código do IBGE
Tendo o código do IBGE no nosso objeto “pg”, podemos então unir os nossos dados ao objeto do tipo espacial do R. Ou seja, iremos realizar um “merge” entre a variável “shp” (shapefile) e a variável “pg” (dataset de pontos ganhos). Esta junção irá retornar um data frame espacial, e terá os dados que precisamos para exibir no mapa.
brasileiropg <- merge(shp,pg, by.x = "CD_GEOCUF", by.y = "Código.UF")
Para se ter uma ideia, segue abaixo a imagem do RStudio de como o R armazena os dados em um data frame espacial:
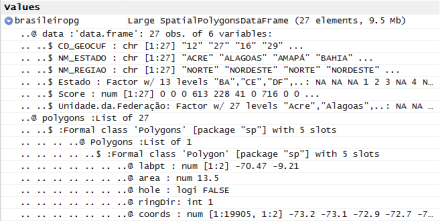
Objeto do tipo “SpatialPolygonsDataFrame”
6) Realizando o tratamento e a formatação do data frame espacial
Agora iremos realizar as últimas transformações no objeto antes de gerar o mapa. A primeira é passar as coordenadas de latitude e longitude para o objeto, utilizando a função proj4string ; a segunda é converter os dados da coluna “NM_ESTADO” para a formatação UTF-8, e a terceira é substituir os valores para os estados que não tem nenhum ponto ganho de “NA” para zero.
proj4string(brasileiropg) <- CRS("+proj=longlat +datum=WGS84 +no_defs")
Encoding(brasileiropg$NM_ESTADO) <- "UTF-8"
brasileiropg$Score[is.na(brasileiropg$Score)] <- 0
7) Gerando o mapa
Finalizadas as etapas de importação e organização dos dados, podemos finalmente gerar o nosso mapa.
Inicialmente vamos escolher as cores para o nosso mapa. Utilizando o pacote RColorBrewer temos acesso a várias paletas de cores. Para consultá-las, basta utilizar no R o comando display.brewer.all():
Paleta de cores do pacote “RColorBrewer”
No nosso exemplo será escolhida a paleta de cores (“Blues”).
Para plotar o mapa existem várias opções de pacotes disponíveis no R. No nosso caso vamos utilizar o pacote Leaflet, que possui uma boa interatividade (é possível clicar nos estados e visualizar os valores de pontuação).
O script para gerar o mapa ficou desta forma:
pal <- colorBin("Blues",domain = NULL,n=5) #cores do mapa
state_popup <- paste0("<strong>Estado: </strong>",
brasileiropg$NM_ESTADO,
"<br><strong>Pontos: </strong>",
brasileiropg$Score)
leaflet(data = brasileiropg) %>%
addProviderTiles("CartoDB.Positron") %>%
addPolygons(fillColor = ~pal(brasileiropg$Score),
fillOpacity = 0.8,
color = "#BDBDC3",
weight = 1,
popup = state_popup) %>%
addLegend("bottomright", pal = pal, values = ~brasileiropg$Score,
title = "Pontos Conquistados",
opacity = 1)
O mapa gerado ficou conforme a imagem abaixo:

Mapa de pontos ganhos no Campeonato Brasileiro por estado
Observações:
Os scripts e os arquivos necessários para reproduzir este exemplo se encontram neste diretório do GitHub . O script foi testado na versão R-3.3.2. Lembre-se de instalar no R os pacotes necessários!
Este mapa está publicado na web através de um aplicativo no Shiny (isto já é assunto para um outro post…). Quem quiser visualizar e interagir com o mapa, basta clicar aqui.
Referências: