
Durante o programa Bate Bola, da ESPN, do dia 12/12/2016, foi solicitado aos telespectadores que enviassem suas seleções ideais dos melhores jogadores do Campeonato Brasileiro 2016 utilizando a hashtag #bateboladebate. A ideia deste post é mostrar como obter dados dos tweets enviados no programa neste dia e realizar a contagem dos nomes dos jogadores que foram mais citados. Assim, conseguiremos demonstrar uma aplicação real da utilização de Text Mining, extraindo dados do Twitter e montando uma seleção com os jogadores mais mencionados pelos torcedores. Vamos utilizar a ferramenta R, que permite trabalharmos com dados de redes sociais e realizarmos a limpeza dos dados. Pra quem não conhece, o R é uma ferramenta de análise de dados e que possui uma linguagem própria para manipulação dos dados.
Extraindo os tweets
Para realizar a captura dos dados do Twitter, são necessárias 3 etapas:
1- Criar uma aplicação do Twitter utilizando o Twitter Apps (para o nosso exemplo, foi criada a aplicação “twitterbuscacomr”, conforme imagem abaixo);

2- Criar as configurações de autenticação;
3- Executar a busca pela palavra-chave (podendo-se definir o número de tweets, a data de início e a data de término).
Para realizar estas etapas recomendo utilizar este link, onde todos estes passos estão muito bem detalhados (inclusive com os scripts para serem executados no R).
No nosso caso, iremos buscar os tweets que utilizaram a hashtag #bateboladebate entre os dias 12/12/2016 e 13/12/2016. A imagem abaixo mostra alguns exemplos de tweets interessantes para o nosso objetivo de montar a seleção do campeonato com base nos tweets:

Feitas todas as etapas necessárias para realizar a conexão com o Twitter, o script para buscar os tweets no R ficou assim:
search.string <- “#bateboladebate”
no.of.tweets <- 1106
batebola <- searchTwitter(search.string, no.of.tweets,since = “2016-12-12”,
until = “2016-12-13”,
lang=”pt”)
Limpando os dados
Agora nós já temos os dados de 1106 tweets que foram capturados de acordo com a nossa busca. Porém, para realizar a contagem dos termos que mais aparecem, será necessário um processo de limpeza do texto, deixando somente o que é realmente importante para o resultado final. Por exemplo, vejam o resultado de um dos tweets originais (número 1023 na busca):

Tweet original
Neste tweet algumas palavras possuem acento, como o jogador Moisés, por exemplo. Porém em outros tweets o nome Moises está sem acento, sendo que se trata do mesmo jogador. Para que isso não ocasione um erro na contagem, precisamos remover os acentos, para que todas os votos sejam computados para um só jogador. O script abaixo realiza esta conversão:
dados <- twListToDF(batebola) #convertendo lista em data frame
dados_str <- stri_trans_general(dados$text,’Latin-ASCII’) #removendo acentuação das palavras
O tweet agora ficou dessa forma, após remoção dos acentos:

Tweet após remoção dos acentos
Para finalizar as transformações no texto, iremos remover caracteres que não irão ser importantes para nossa análise, como pontuação, números, palavras muito comuns ou funcionais na linguagem (que chamamos de stopwords), além de caracteres de uso comum no Twitter. Podemos utilizar o script do R a seguir:
dados_transf <- as.data.frame(dados_str)
corpus <- Corpus(VectorSource(dados_str))
corpus <- tm_map(corpus, stripWhitespace) #realizando tratamento de múltiplos espaços
corpus <- tm_map(corpus, tolower) #transformando em letra minúsucula
corpus <- tm_map(corpus, function(x) gsub(‘@[[:alnum:]]*’, ”, x)) #removendo menções
corpus <- tm_map(corpus, removePunctuation) #removendo pontuação
corpus <- tm_map(corpus, removeNumbers) #removendo números
corpus <- tm_map(corpus, function(x) gsub(‘http[[:alnum:]]*’, ”, x)) #removendo URLs
corpus <- tm_map(corpus, removeWords, c(stopwords(‘portuguese’), ‘bateboladebate’,’rt’)) #removendo “stopwords”
corpus_text <- tm_map(corpus, PlainTextDocument)
O resultado do tweet após todas as transformações acima ficou assim:

Tweet após transformações
Análise dos resultados
Tendo sido feita a transformação dos tweets, podemos criar o que chamamos de “term-document matrix”, que é uma matriz utilizada para contar a quantidade de vezes que um termo aparece em cada documento (no nosso exemplo, em cada tweet). Utilizaremos o script do R abaixo para gerá-la:
#Create Term Document Matrix
tdm <- TermDocumentMatrix(corpus_text, control=list(minWordLength=1))
term.freq <- rowSums(as.matrix(tdm))
term.freq <- subset(term.freq, term.freq >=50)
df <- data.frame(term = names(term.freq), freq = term.freq)
View(df[order(-df$freq),])
O resultado é a tabela a seguir:
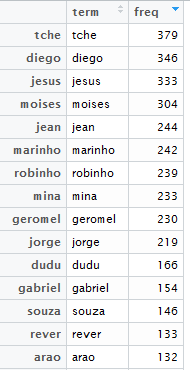
Trabalho concluído? Certamente não. Quando trabalhamos com análise de dados, é fundamental ter conhecimento do negócio e dos dados, de maneira geral. Por isso é muito importante pedir o apoio de alguém de entenda da área de conhecimento (no caso, o futebol), para que o resultado seja o mais correto possível.
No exemplo, podemos perceber que o termo mais encontrado no tweets foi “tche”. Quem acompanha futebol sabe que existe um jogador do Palmeiras que se chama Tchê Tchê. Logo, quem escolheu o Tchê Tchê para a sua seleção citou a expressão “tche” duas vezes em cada tweet, o que corresponde a um único voto.
Outro caso interessante é do nome Diego. Um dos jogadores de destaque do campeonato foi o Diego do Flamengo. Porém, o Diego Souza do Sport também fez uma ótima competição. Como diferenciar quem votou em Diego ou Diego Souza? Uma forma de analisar é observando que a palavra “souza” apareceu 146 vezes, o que indica o voto para o Diego Souza nestes casos.
Seleção do Campeonato Brasileiro 2016 do tweets do Bate Bola ESPN
Realizando as seguintes adequações:
- Tchê Tchê = tche / 2 = 379 / 2 = 189,5
- Diego = diego – souza = 346 – 146 = 200
- Gabriel Jesus = jesus + gjesus = 333 + 31 = 364
Temos a seguinte seleção dos mais votados:

Observação: Os scripts foram testados na versão R-3.3.2 do R. Todos os scripts utilizados neste post e os dados estão disponíveis no GitHub.
Referências:

Republicou isso em Alex Souza.
Ola
Como ficaria isso em python??
Olá.
Pergunta interessante. Segue um link de um exemplo parecido de extração de tweets utilizando Python.
http://nealcaren.web.unc.edu/an-introduction-to-text-analysis-with-python-part-1/
Seriam necessárias algumas adaptações, mas acho que você já consegue ter uma referência seguindo estes passos.
Se conseguir reproduzir, compartilhe aqui nos comentários do blog!
Abraços.